


Database changes are hard
Database change difficulty = team size ^ team size

Database changes are complex. I’ll list my top 10 difficult changes, but there are 100 more!
Changing column types and converting existing data in those columns
Syncing manual data changes across environments, especially reference data
Adding new columns
Indexes, finding the right ones and adding new ones
Table creation
Dropping unused tables/columns and having confidence
Writing views useful for the team
Making schema changes for denormalization trade-offs
Synchronizing schema changes across environments
Renaming tables and columns
Database change difficulty = team size ^ team size
Database changes become exponentially harder with a larger team and are highly time-consuming for large organizations.
Let’s take a simple example of adding a new column to a database table
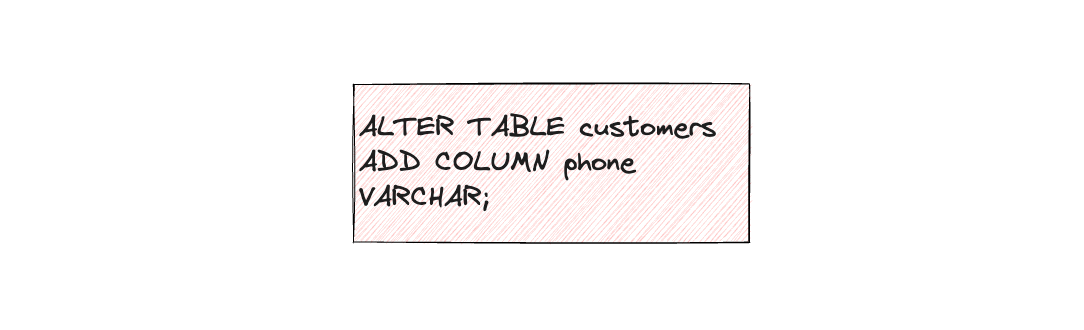
It is easy for one developer to make a change

Harder for three developers to make database changes

Almost impossible for thousands of developers to make database changes

Yikes!
Applications must be aware of a database schema version
Coordinated releases
Communication to all application teams about the change
Application development moves slow
The list goes on!
Schema-less doesn’t solve database change management
Even when a database is schema-less, there must be central data management across application teams and a concept of a schema, even if the database does not manage it. Some applications will add the idea of a schema to a library and update that shared library. Other applications may use a microservice with various API endpoints. However, the same problem still exists for coordinating changes across many applications.
It’s even worse for non-developers!
The simple example above is for adding a new column focused on developers. How about users who aren’t developers? Maybe they want to fix some data or add additional reference data.
Please help me add this reference data set on zip codes and states. I can’t fix my dashboard queries without it.

There are better ways for teams to work together and build data-driven organizations, Especially with time spent waiting, coordinating system changes, and orchestrating communication between teams.
Sort
At Sort, we’re working to solve the complexities of database collaboration by harnessing Github workflows (think pull request workflows and social coding). We’ll initially support Postgres and Snowflake but plan to add support to all database platforms. We’re close to opening up Sort for early-access users. Sign up to get notified here: sort.xyz.
In some cases a database proxy might help to isolate the database topology from the application layer, we recently wrote about that - https://packagemain.tech/p/the-developers-guide-to-database