
Simple Postgres Query Optimization: Avoid the Sequential Scan
Optimizing Postgres queries can seem complicated, let's make it simple.

Optimizing Postgres queries can seem complicated, especially when considering the information returned from the EXPLAIN command, e.g.
EXPLAIN select * from users where username = ‘superman’Output:
Seq Scan on user_account (cost=0.00..1.01 rows=1 width=126)
Filter: (("character")::text ~~ 'batman'::text)The best place to start when optimizing a query is to ensure you are avoiding sequential scans and using an index.
What is a sequential scan?
If we look for the user with username = ‘superman’, Postgres does not know how to quickly access the correct rows where username = ‘superman’. If there are 100 million users in the database, Postgres may need to check all 100 million rows to find the rows containing username = ‘superman’
Indexes to the rescue
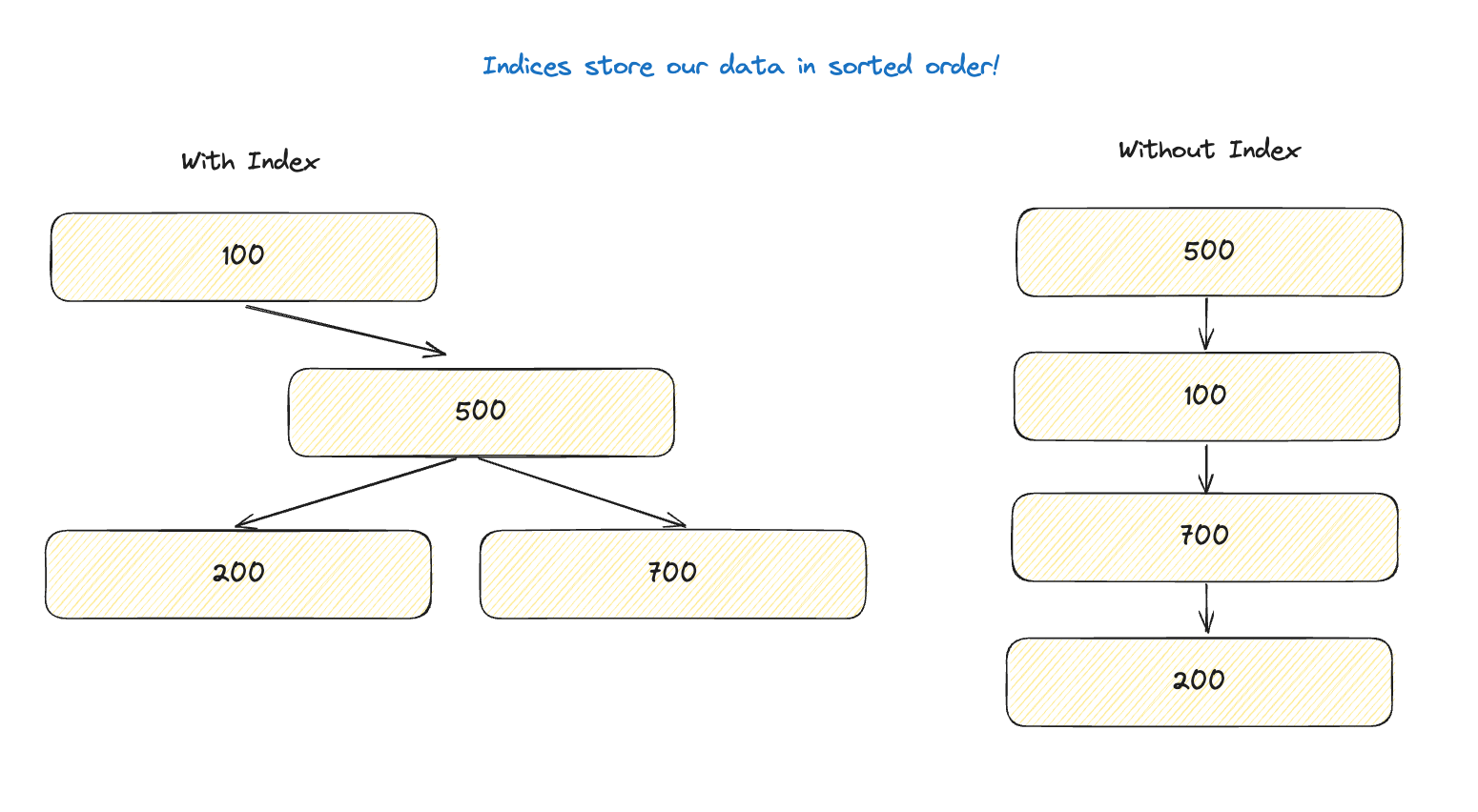
By defining an index, we can create a data structure within the database for finding rows and data as quickly as possible.
Now, when we look for username = ‘superman’, we can use an index to find the rows we’re interested in without looking at all 100 million rows in the database, which is a huge performance boost!

A simple example
Let’s walk through a simple example to show the difference between a query that uses an index vs a query that doesn’t.
// Let’s create a simple user table, with character and score
CREATE TABLE user_account (
user_id serial PRIMARY KEY,
character VARCHAR ( 50 ),
score INT
);
// Insert 4 sample user accounts
INSERT INTO user_account (character, score) VALUES('superman',100);
INSERT INTO user_account (character, score) VALUES('batman',500);
INSERT INTO user_account (character, score) VALUES('superwoman',700);
INSERT INTO user_account (character, score) VALUES('joker',200);Now let’s run a simple query to find the user_accounts with the ‘batman’ character:
explain select * from user_account where character = 'batman'Output:
Seq Scan on user_account (cost=0.00..16.62 rows=3 width=126)
Filter: (("character")::text = 'batman'::text)No index was used, see the Seq Scan row at the very beginning!
Let’s create an index in Postgres for the username column:
CREATE INDEX character_index ON user_account(character);Postgres will now use the index we just defined!
Cases where sequential scans may be faster than indices
If the query result contains greater than 10% of the rows in the table, sequential scans may be more efficient then using an index, and preferred by the Postgres query planner.
A Postgres index only contains a small amount of information about finding the row in the database, and the row must still be retrieved from disk to finalize the query result. If the query requires fetching a lot of rows, a sequential scan will be preferred since additional lookups (compared to using an index) won’t be needed.
Regular expressions
Be careful with regular expressions and indices, it can be hard to efficiently use an index when your query uses a regular expression.
explain select * from user_account where character LIKE 'b%'Output:
Seq Scan on user_account (cost=0.00..1.01 rows=1 width=126)
Filter: (("character")::text ~~ 'b%'::text)Sorting
Sorting can also add additional considerations to index usage.
For example, let’s sort by score desc, and limit to the top 5, to show a leaderboard:
select * from user_account order by score desc limit 5This query uses a sequential scan, which isn’t good, even though it uses an index to match the username.
We can add an index for the sort field to improve performance.
CREATE INDEX score_idx ON user_account(score);A Simple Primer
In our examples, we used a single field index, however, compound indices (more than one column) are important for more complex use cases. We’ll walk through various ways to create and optimize compound indices in a future post.
At Sort, we’re building a supercharged database collaboration platform for Postgres and Snowflake. Learn more and sign up to get early access at sort.xyz today.